Explaining RL Agents in Atari Games #
Authors: Amir Bikineyev, Dzhavid Sadreddinov
Link to the source: github
Introduction #
By now, many people have at least heard of Atari games — and some have even played them. Classics like our beloved Pong, Breakout, Space Invaders, and others come to mind (see images below). While these games were originally popular in the late 20th century purely for entertainment, today they serve a different purpose for many: their simplicity makes them ideal environments for experimenting with reinforcement learning (RL) agents.
Today, we’ll join that group — but with a slightly different goal. Our task is to explore how a neural network “thinks” and what it pays attention to. To do this, we’ll implement the Grad-CAM method on a convolutional neural network.

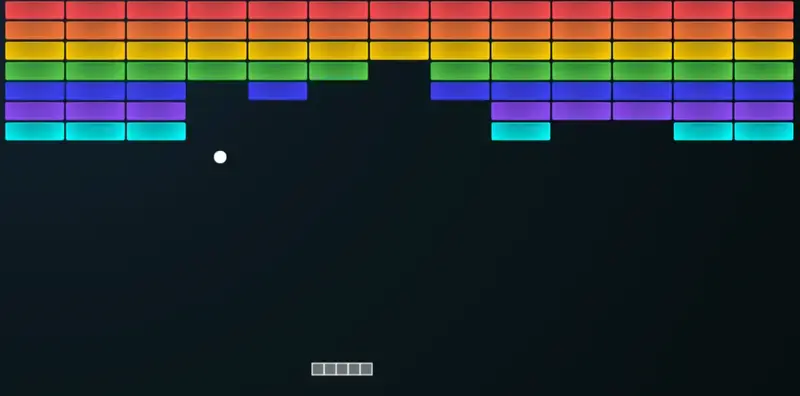

Agent Overview #
The Q-value estimator #
For our agent model, we used the Deep Q-Network (DQN) architecture. The model consists of two main components: a feature extractor and a Q-value head.
The feature extractor is a convolutional neural network (CNN) that takes as input a stack of 4 consecutive frames from the game environment. It looks like:
self.__features = nn.Sequential(
nn.Conv2d(4, 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU()
)
The Q-value head can take one of two forms:
In the standard DQN setup, it’s a simple linear network that outputs a single Q-value for each possible action.
In the distributional DQN version, instead of outputting a single Q-value, it predicts a probability distribution over a set of fixed values (called “atoms”) — for example, 51 evenly spaced points between –10 and 10. These outputs (logits) are passed through a softmax to produce a probability distribution, and the final expected Q-value is computed as a weighted average using the formula ⟨probabilities, support⟩.
The Q-value head:
self.__head = nn.Sequential(
nn.Linear(64*7*7, 512),
nn.ReLU(),
nn.Linear(512, out_size)
)
Game process #
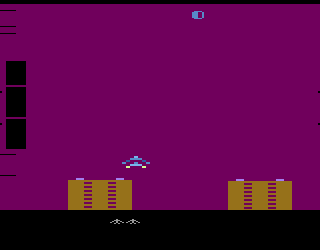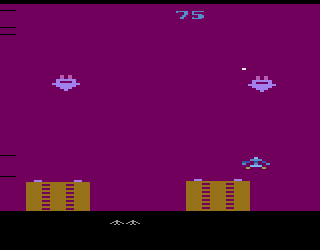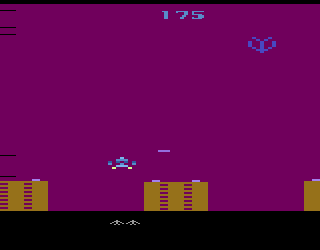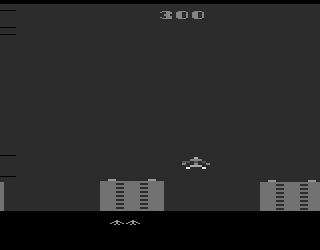
For each atari game we have taken trained model and environment in the Arcade Learning Environment (ALE). Before make decision we give to the model previous 4 frames and each chosen action of the model will be held in future 4 frames. The model take each action via ε-greedy policy.
Below you can see the examples of playing:
CAM methods #
What is Grad-CAM? #
Gradient-weighted Class Activation Map (Grad-CAM) used to generate heatmaps that highlight the important regions of an image contributing to the model’s performance.
How it Works #
In general the Grad-CAM algorithm working as follows:
Picking a layer which will be used for explanation. Usually the last layers are used because they’re process the high level features that will be understandable by humans
Then we passing the input that we want to explain through our model and particularly through our picked layer to obtain feature-map
Then we need to calculate the gradients of the predicted class/decision via backward pass with respect to feature maps in the chosen layer. Mathematically speaking:
$$ \alpha_k^c = \frac{1}{Z} \sum_{i,j} \frac{\partial y^c}{\partial A_{i,j}^k} $$
where \( Z \) is the size of the feature map (width × height), \(y^c\) is the score for class \(c\) , and \(A_{i,j}^k\) represents the activations of the \(k^{\text{th}}\) feature map at spatial location \((i, j)\) .
After all we need to obtain importance map by multiplying each feature map \(A_{}^k\) by the \(\alpha_k^c\) and summarize to obtain heatmap
$$ L_{\text{Grad-CAM}}^c = \text{ReLU} \left( \sum_k \alpha_k^c A^k \right) $$
Then the resulting image we upsampling and overlaying on top of the input image to vizualize the regions that contribute most to the model’s decisions.
What is Grad-CAM++? #
Grad-CAM++ is an enhanced version of Grad-CAM that produces more precise and localized heatmaps.
Differences from Grad-CAM #
- Grad-CAM++ replaces this uniform averaging with a pixel-wise weighted sum that uses both second- and third-order gradients, emphasizing locations where small activation changes greatly affect the class score: $$ \alpha_k^c = \sum_{i,j} \left[ \frac{ \frac{\partial^2 y^c}{(\partial A_{i,j}^k)^2} }{ 2\frac{\partial^2 y^c}{(\partial A_{i,j}^k)^2} + \sum_{i,j} A_{i,j}^k \frac{\partial^3 y^c}{(\partial A_{i,j}^k)^3} } \right] $$
What is FullGrad? #
FullGrad is a complete gradient-based explanation method that aggregates gradient information from all layers of a neural network (not just one convolutional layer) to explain model decisions. Unlike Grad-CAM, which focuses on a single layer, FullGrad accounts for biases and activations across the entire network, providing more holistic explanations.
How it works? #
- Firstly we need to compute calculate gradients for every layer of the target class/decision of the model with respect to both activations and biases \(\nabla_{A^l} y^c \) (activation gradients) \(\nabla_{b^l} y^c \) (bias gradients)
- Then we need to combine gradients and biases across all layers into a single saliency map: $$ L_{\text{FullGrad}}^c = \sum_l \left( A^l \odot \nabla_{A^l} y^c + b^l \odot \nabla_{b^l} y^c \right) $$ ⊙ - element-wise multiplication
- After all the final map is upsampled and overlaid on the input image, similar to Grad-CAM.
CAM methods example #
Below you can see how heatmaps for each CAM method is works
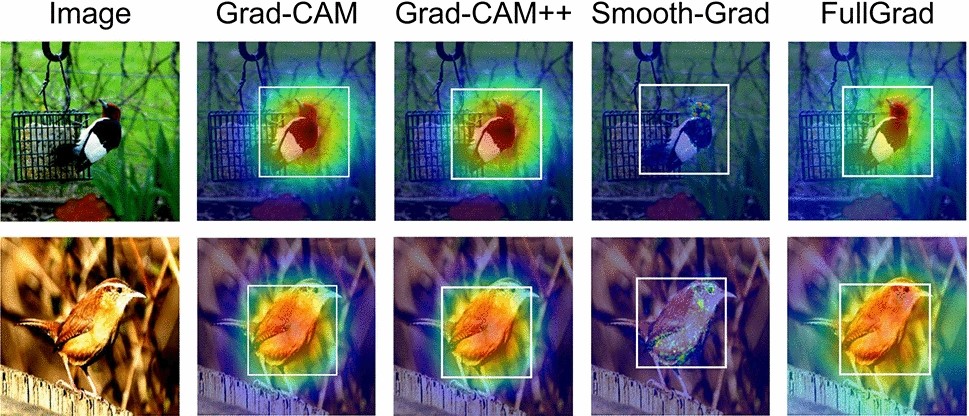
What is FullGrad++ (Multi-layer Grad-CAM++)? #
FullGrad++ is an advanced explainability method that extends the precision of Grad-CAM++ across multiple layers, combining it with FullGrad’s principle of complete layerwise aggregation.
Whereas Grad-CAM++ traditionally analyzes a single layer, FullGrad++ evaluates multiple convolutional and normalization layers, assigning them weights based on their activation magnitudes. This allows the method to capture both deep and shallow features contributing to the model’s prediction, producing detailed and spatially precise saliency maps.
How it Works #
The FullGrad++ method involves the following steps:
Hooking All Layers:
- Hooks are registered on all layers that contain activations (e.g.,
Conv2d,BatchNorm2d) - For each layer, we collect:
- Forward activations \( A^l \)
- First-order gradients \( \nabla_{A^l} y^c \)
- Hooks are registered on all layers that contain activations (e.g.,
Second-Order Weight Computation (Grad-CAM++ style):
- For each activation map, compute:
- \( g^1 = \frac{\partial y^c}{\partial A^l} \)
- \( g^2 = (g^1)^2 \) , \( g^3 = g^2 \cdot g^1 \)
- We then calculate the Grad-CAM++ importance weights: $$ \alpha_k^c = \frac{g_k^2}{2g_k^2 + A_k \cdot g_k^3 + \epsilon} $$ where \( A_k \) is the activation and \( g_k \) is the gradient of the \( k \) -th feature map
- For each activation map, compute:
Generate Layer-wise CAMs:
- Using weights \( \alpha_k^c \) , compute layer-wise saliency maps: $$ \text{CAM}_l = \text{ReLU}\left(\sum_k \alpha_k^c A_k^l\right) $$
Aggregation Across Layers:
- Each layer’s saliency map is resized to the input resolution
- The final saliency is a weighted average of all layer maps: $$ L^c = \frac{1}{\sum_l w_l} \sum_l w_l \cdot \text{CAM}_l $$ where \( w_l \) is the average activation energy of the layer, used as a weight to reflect its relevance
Implementation Highlights #
Activation-weighted Aggregation: Each layer contributes to the final explanation proportionally to its average activation magnitude, serving as a dynamic and data-driven weighting scheme.
Efficient Layer Registration: Hooks are registered once on initialization. During inference, all necessary data (activations, gradients) are gathered in one forward-backward pass.
Standalone and Framework-agnostic: No external libraries (like
pytorch-grad-cam) are used. The implementation is pure PyTorch, ensuring flexibility and transparency.Normalization and Smoothing: The output saliency map is resized and normalized for visual overlay. Additional Gaussian smoothing can optionally be applied to reduce noise and enhance interpretability.
Advantages of This Approach #
Precision: Second-order weighting from Grad-CAM++ enables more accurate focus on fine-grained regions.
Completeness: Multi-layer aggregation captures the full feature hierarchy of the model.
Flexibility: Supports any architecture with convolutional and normalization layers.
Interpretability: Dynamic weighting makes it easier to understand which layers and features contribute most.
Results #
Here we can see the results of explanation for the decisions of AtariNet for different games by FullGrad and our approach:
Breakout: #
Our approach #

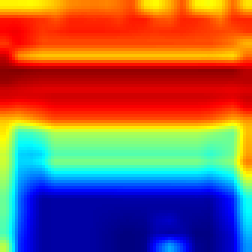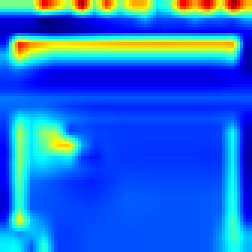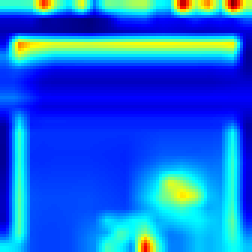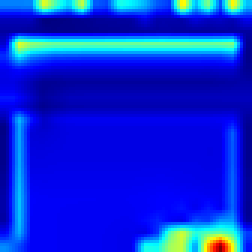
FullGrad #

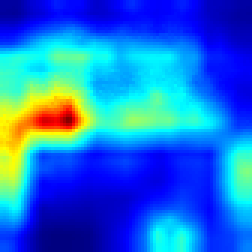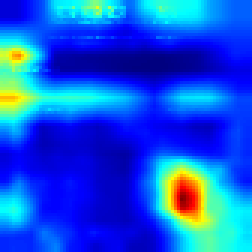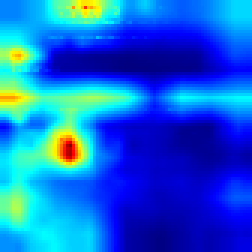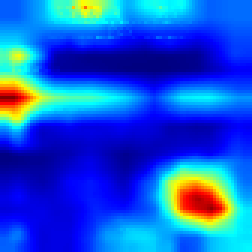
Both algorithms follows the ball and highlights that the ball has great impact on making decision which approves that model make decision as people do. However our approach provides more sharp CAM and the blob is not too wide, which more accurately shows the explanation.
Pong: #
Our approach #


FullGrad #

The same observation for Pong environment. The model’s attention is on the ball and moving platforms, which is correct.
Enduro #
Our approach #

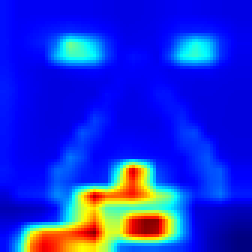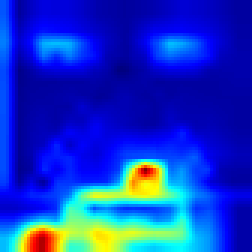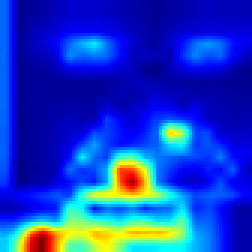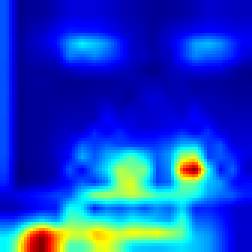
FullGrad #

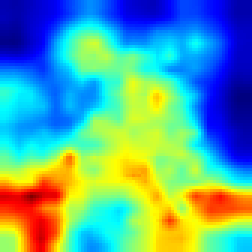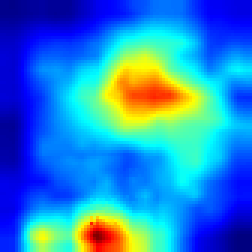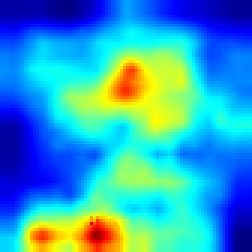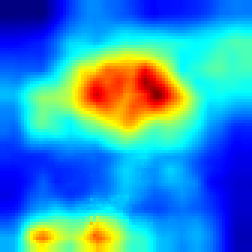
For Enduro environment we can see that while FullGrad approach allows us just to see that model is watching on the road, our approach gives more detailed vision that model “watches” cars.
VideoPinball #
Our approach #


FullGrad #

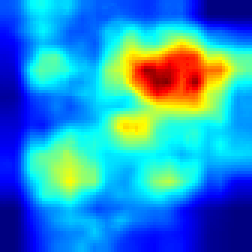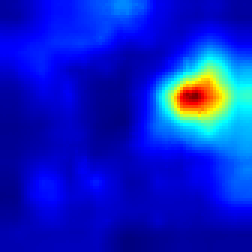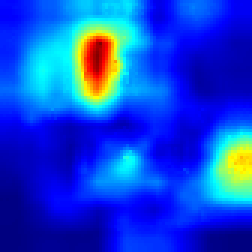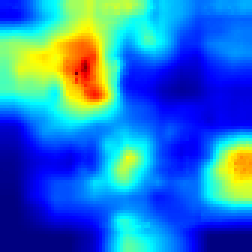
And in the VideoPinball game Fullgrad explaines models decision by showing, that model is concentrated on ball, while our approach highlights the more accurate ball activation and two handles and the bottom which model is controlling.
Conclusion #
Our experiments across multiple Atari games (Breakout, Pong, Enduro, and Video Pinball) demonstrated that the agent’s attention aligns with intuitive gameplay strategies—focusing on the ball, player-controlled elements, and key environmental objects. \(\)