Integrated Gradients and Attention Visualization for Cost-efficient adaptation method #
By Dmitrii Kuzmin and Yaroslava Bryukhanova
Repo link: [https://github.com/1kkiRen/xAI]
Getting Started #
Explainable AI methods help us understand what drives a model’s decisions. Here, we compare three approaches: Integrated Gradients (IG), attention visualization, and embedding influence analysis — using two transformer-based language models:
- meta-llama/Llama-3.2-1B-Instruct
- ikkiren/research_TS
Our aim is to see which input tokens influence the models most and how attention patterns reflect their focus.
Models at a Glance #
- meta-llama/Llama-3.2-1B-Instruct: A 1 billion-parameter Llama model tuned for conversational tasks.
- ikkiren/research_TS: A custom model fine-tuned for Russian text, with special handling for morphology and syntax.
Methods Overview #
1. Integrated Gradients #
Integrated Gradients calculates attribution scores by integrating gradients from a baseline (zero) embedding up to the actual input embedding. We used 50 steps and tracked the convergence delta for each model.
IG provides a principled way to assign credit to each input token for the model’s prediction. Specifically:
- We approximate the integral over the embedding path by sampling 50 points between the baseline and the input.
- For each step, we compute the gradient of the target logit with respect to the interpolated embedding.
- Attributions are obtained by summing the gradients and scaling by the difference from baseline.
- We sum attributions across embedding dimensions to get a single score per token.
2. Attention Visualization #
We pulled attention weights from layer 0, head 0 of each model and created heatmaps to show token-level focus during prediction.
Attention weights indicate how much each token attends to every other token in a given head and layer.
- Extracted raw attention tensors directly from the model’s forward pass (no gradient tracking needed).
- Selected layer 0, head 0 as a representative case to illustrate global versus local focus.
- Visualized weights as a heatmap where rows correspond to queries and columns to keys.
- Normalized attention scores to sum to one per query token for clearer interpretation.
- Implementation: Used Matplotlib for heatmap plotting, with tokens labeled along the axes.
3. Embedding Influence Analysis #
- Ablation: We zeroed each token’s embedding and noted changes in the output logit. A big drop means the token is important.
- Sensitivity: We added small Gaussian noise to each embedding, repeated the test, and measured the average output change. Higher variance indicates greater sensitivity.
To quantify embedding importance beyond gradients:
- For ablation, we replaced a single token’s embedding with a zero vector, ran a forward pass, and recorded the delta in the target logit.
- For sensitivity, we sampled Gaussian noise with σ=0.1 added to one embedding at a time, repeated for 10 random draws, and computed the standard deviation of the resulting logits.
- Ablation captures direct contribution, while sensitivity captures how robust the prediction is to small changes in each embedding.
- Both measures complement IG by revealing inhibitory versus supportive roles and points of instability.
Experimental Setup #
- Data & Preprocessing:
- Trim whitespace and normalize Unicode.
- Tokenize with each model’s tokenizer.
- Pad or truncate to 128 tokens.
- Implementation: Python notebooks using Hugging Face Transformers and custom XAI utilities.
Results #
Integrated Gradients #
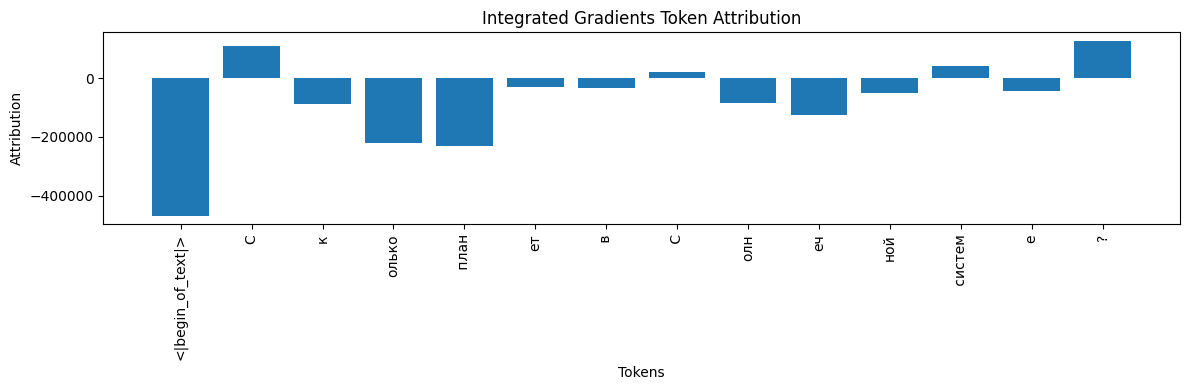
IG attributions for meta-llama/Llama-3.2-1B-Instruct
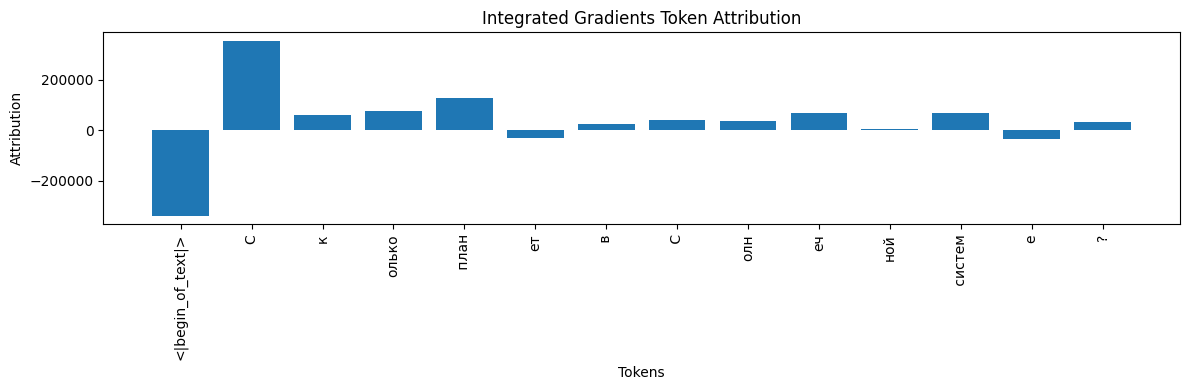
IG attributions for ikkiren/research_TS
Raw Scores & Deltas #
meta‑llama/Llama‑3.2‑1B-Instruct
{
"<|begin_of_text|>": -468275.8125,
"С": 110818.0,
"к": -88699.765625,
"олько": -219594.265625,
" план": -232745.015625,
"ет": -29436.662109375,
" в": -34299.03125,
" С": 20781.52734375,
"олн": -84084.0390625,
"еч": -124966.0234375,
"ной": -48963.0,
" систем": 40694.140625,
"е": -44074.41015625,
"?": 126299.6328125
}
Absolute convergence delta: 1 048 421.3125
ikkiren/research_TS
{
"<|begin_of_text|>": -337049.46875,
"С": 352206.6875,
"к": 61753.21484375,
"олько": 74791.2890625,
" план": 125668.390625,
"ет": -31054.927734375,
" в": 24036.47265625,
" С": 38717.6484375,
"олн": 36866.60546875,
"еч": 66281.859375,
"ной": 6265.0625,
" систем": 66483.28125,
"е": -36235.12890625,
"?": 32296.85546875
}
Absolute convergence delta: 620 490.0625
What the Numbers Tell Us #
- Both models give a large negative IG to “<|begin_of_text|>”.
- meta‑llama: “?” and the first “С” are top positive contributors, while most other subwords have strong negative scores.
- research_TS: The first “С” and " план" score highest, and negative attributions are smaller in magnitude.
- A high |Δ| suggests that the numerical IG estimate can vary widely with nonlinear models.
Attention Visualization #
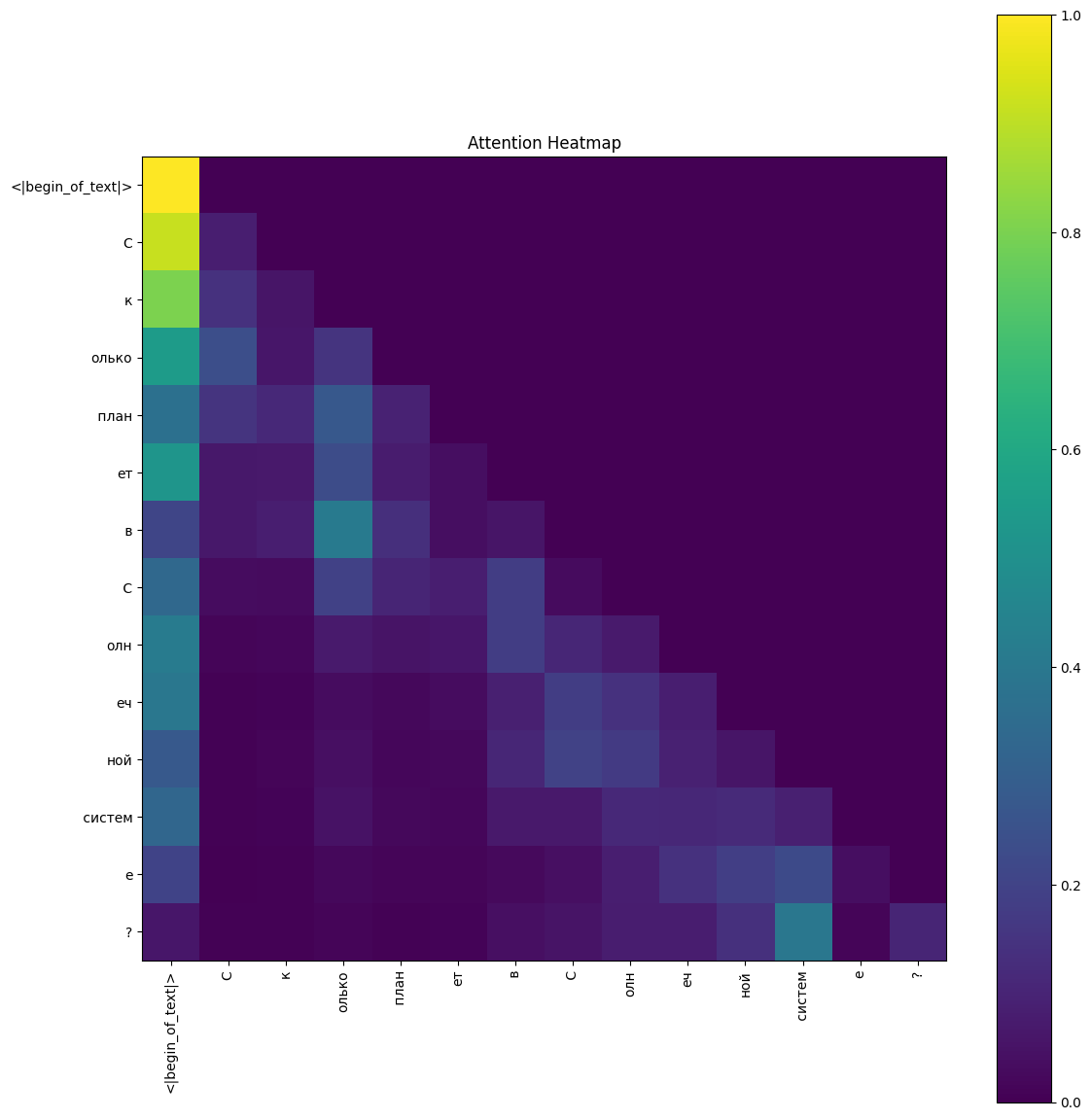
Layer 0, head 0 for meta-llama
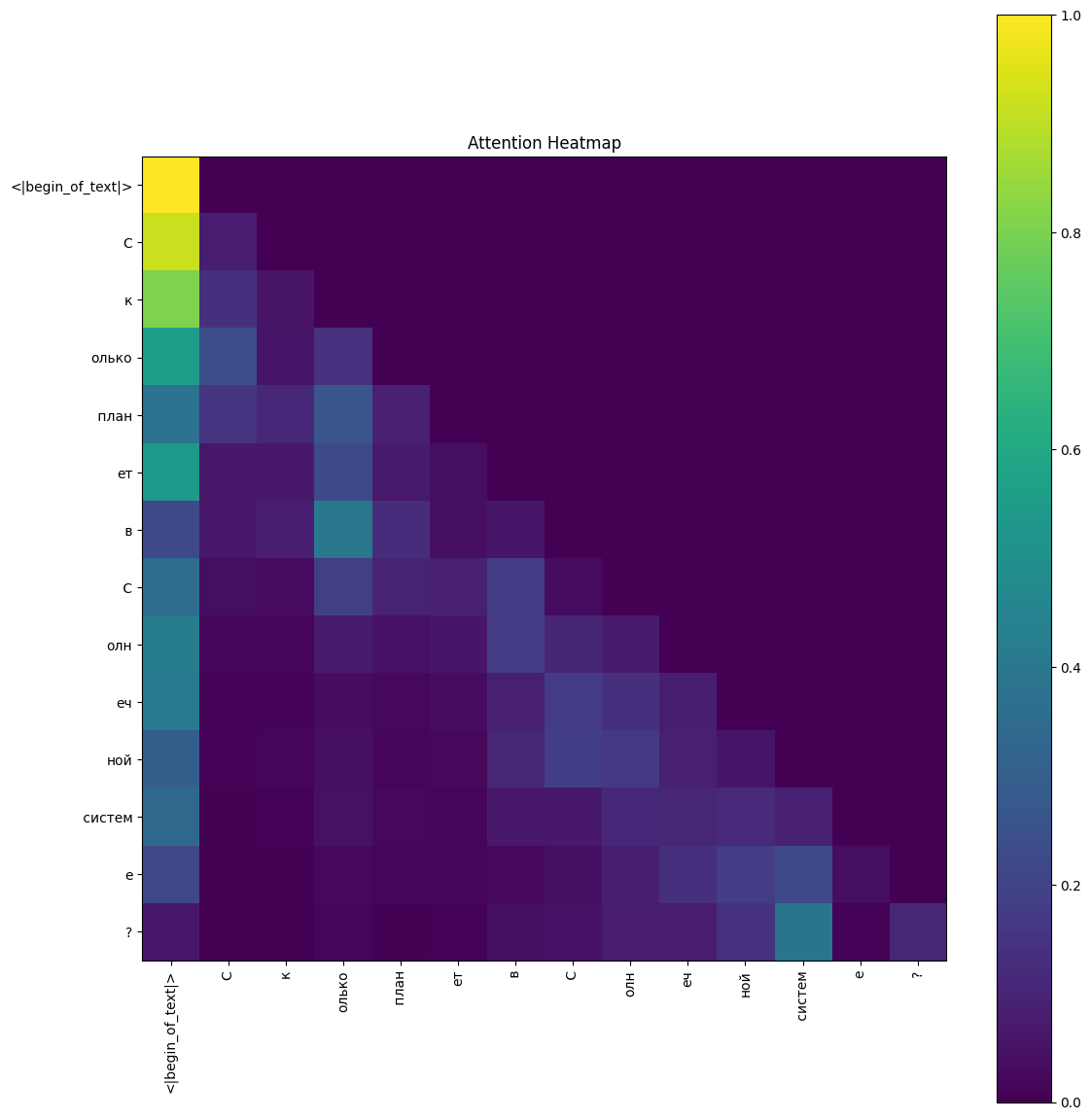
Layer 0, head 0 for research_TS
Key Observations #
- The BOS token (<|begin_of_text|>) strongly attends to itself.
- Most other tokens send the bulk of their attention to the BOS marker instead of neighbors.
- Diagonal (self-attention) values are low (0.05–0.15), suggesting this head acts as a global context gatherer.
- This pattern hints that layer 0, head 0 focuses on overall context rather than local dependencies.
Embedding Influence #
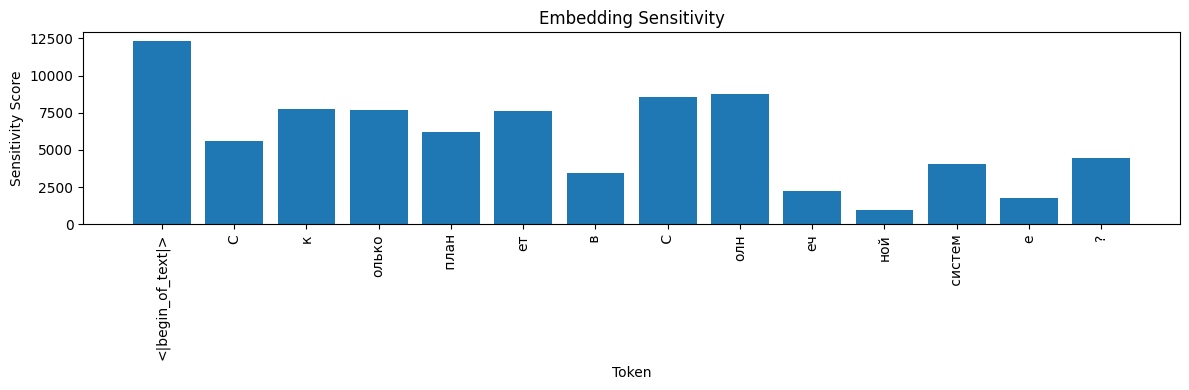
meta‑llama/Llama‑3.2‑1B-Instruct #
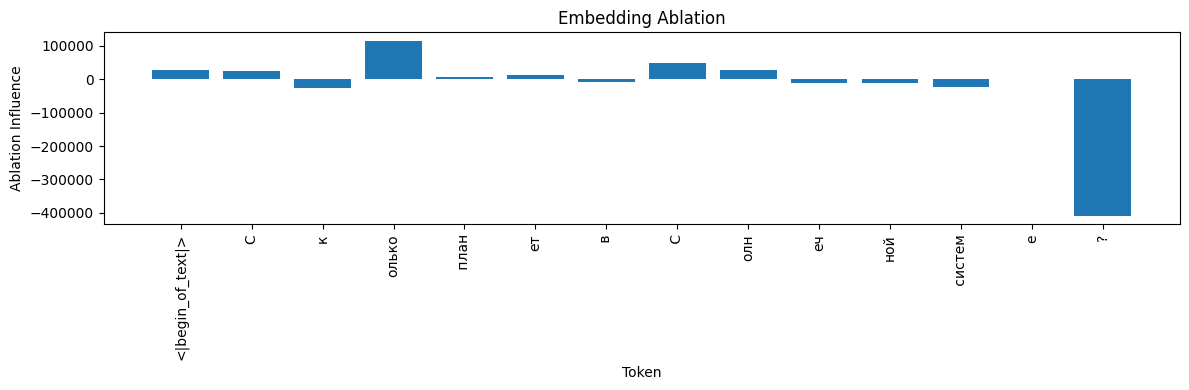
- Ablation: Zeroing “?” boosts the logit (+408 385), so “?” actually inhibits. “олько” is vital (+114 497).
- Sensitivity: The first “С” and “ет” show the highest variance under noise, indicating they’re key for output stability.
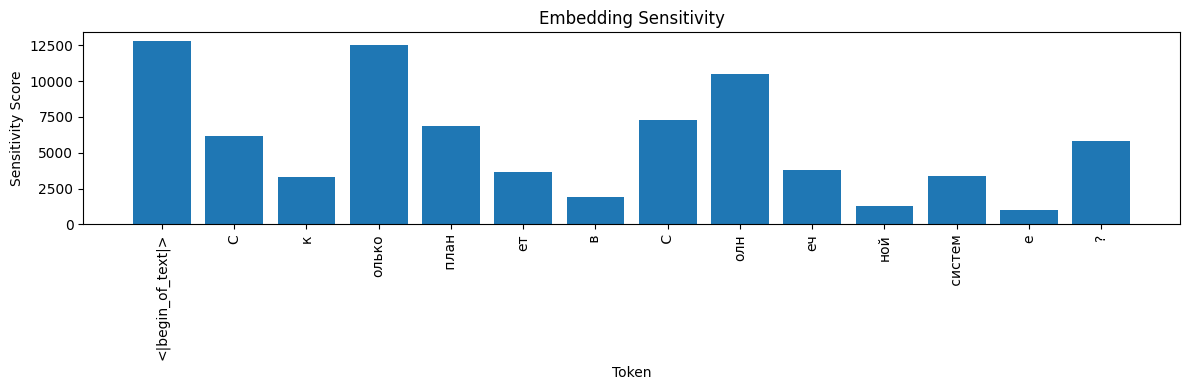
ikkiren/research_TS #
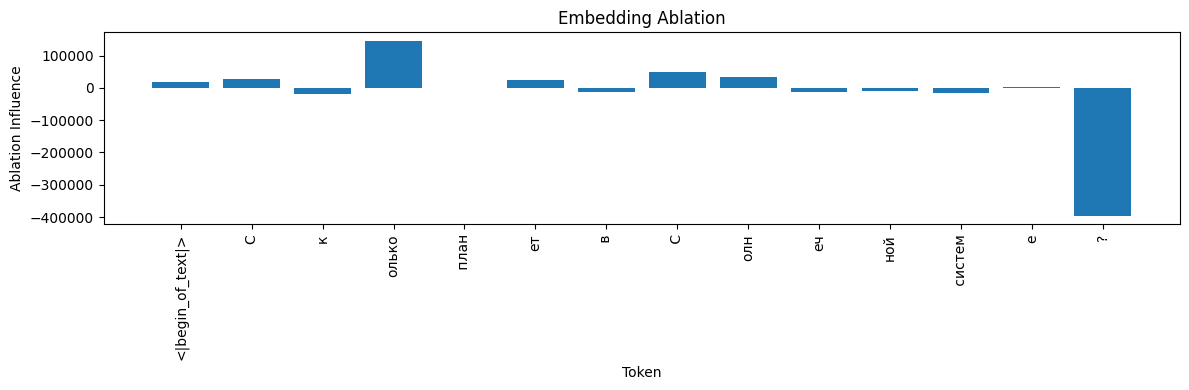
- Ablation: “олько” is crucial (+145 365), while “?” remains inhibitory (−395 674).
- Sensitivity: The BOS token and “?” cause the biggest output swings.
Takeaways #
- Both models: “?” inhibits, “олько” supports.
- IG and ablation agree on which tokens matter; sensitivity highlights instability points.
- Grouping subwords into full words (e.g., “Сколько”) may simplify interpretation.
Discussion #
IG gives us clear numbers for token attributions, while attention maps show where the model looks. meta-llama has sharper peaks in attribution and attention; research_TS spreads importance more evenly.
Limitations #
- We only checked layer 0, head 0 for attention.
- The IG baseline is zero embeddings; other baselines might change insights.
- Analysis is limited to one example.
Next Steps #
- Explore attention across all layers and heads.
- Try other attribution methods (SHAP, LIME).
- Test IG with different baselines and on diverse text samples.
Conclusion #
Combining IG and attention visualization gives a richer view of transformer behavior. This helps researchers and developers understand, debug, and refine their models.