Gradient-based Attribution to Interpret Large Langague Models in text generation #
This page demonstrates how to attribution methods can be used to understand which input tokens influence an LLM’s output. Let’s explore the mathematical foundations of these techniques.
Feature Ablation #
Feature ablation is an approach that measures the importance of features by removing them and observing the effect on the model output.
Mathematical Formulation #
For an input token \(x_i\) , the attribution is calculated as:
\[A(x_i) = f(x) - f(x_{-i})\]Where:
- \(f(x)\) is the model output for the original input
- \(f(x_{-i})\) is the model output when feature \(x_i\) is replaced with a baseline value
- The larger the difference, the more important the feature
Integrated Gradients #
Integrated Gradients (IG) is a gradient-based method that assigns attribution scores by accumulating gradients along a path from a baseline input to the actual input.
Mathematical Formulation #
The formula for Integrated Gradients is:
\[IntegratedGradients_i(x) = (x_i - x'_i) \times \int_{\alpha=0}^1 \frac{\partial F(x' + \alpha \times (x - x'))}{\partial x_i} d\alpha\]Where:
- \(x_i\) is the feature (token embedding)
- \(x'_i\) is the baseline (typically zero embeddings)
- \(\alpha\) is the interpolation parameter
- \(F\) is the model function
In practice, this integral is approximated with a sum:
\(IntegratedGrads^{approx}_i(x) = (x_i - x'_i) \times \sum_{k=1}^{m} \frac{\partial F(x' + \frac{k}{m} \times (x - x'))}{\partial x_i} \times \frac{1}{m}\)Where \(m\) is the number of steps in the approximation.
The Problem with Simple Gradients #
Traditional attribution methods often use gradients (how much the output changes when you slightly change an input feature). However, this approach has a major flaw: in many networks, the gradient might be zero for important features.
Think about a simple function that increases as you increase input x, but flattens out after x=0.8 (stays constant at 0.8 for any input greater than 0.8). If your input is x=1.0, the gradient at that point is zero because the function is flat there. But clearly, x had a huge impact on the output (bringing it from 0 to 0.8)
This happens in real networks with ReLU activations, which create these “flat regions” in the network’s function.
The Core Insight: Integration Along a Path #
The key intuition of integrated gradients is: Don’t just look at the gradient at the final input point; examine how the prediction changes as you gradually transform a neutral baseline into your actual input.
This is like asking: “How did each feature contribute as we built up the input piece by piece from nothing?”
Why a Straight-Line Path? #
The method uses a straight-line path between the baseline and input because:
- It’s mathematically simple
- It preserves symmetry (if two features play identical roles, they get identical attributions)
- It requires no knowledge of the network’s internal structure
How It Actually Works #
Choose a baseline: A neutral input representing the absence of features (like a black image in vision or a zero embedding for text)
Create interpolated inputs: Generate several points along the straight line from baseline to input (like taking 20-300 steps along the path)
Compute gradients at each step: Calculate how each feature affects the output at each interpolated point
Accumulate the gradients: Sum up all these gradients for each feature, scaling by the feature’s difference from baseline
The formula is: IntegratedGrads_i(x) = (x_i - x’_i) × ∫(α=0 to 1) [∂F(x’ + α×(x-x’))/∂x_i] dα
Where x is your input, x’ is your baseline, and F is your model’s function.
Why This Works Better #
This approach ensures:
- Sensitivity: If changing a feature changes the output, it gets non-zero attribution (unlike simple gradients)
- Implementation Invariance: The attributions don’t depend on how the network is implemented, only on what it computes
- Completeness: The attributions add up exactly to the difference between the model’s output at input vs. baseline
In practical terms, this means you get attributions that faithfully reflect which features actually matter for the prediction, making the neural network’s decision process more transparent and understandable.
Demo #
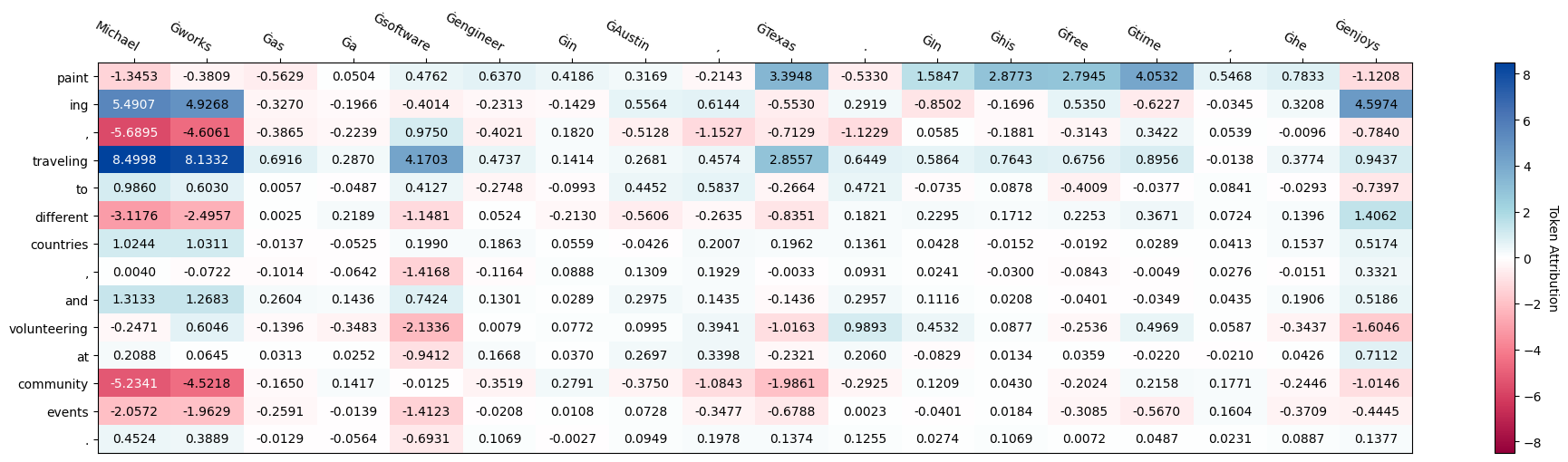
Let’s take this sentence: \(\text{"Michael works as a software engineer in Austin, Texas. In his free time, he enjoys}\) \(\text{painting, traveling to different countries, and volunteering at community events."}\)
We want to so how the how each part of the first part of sentence influences each part in the second part of the sentence
Let’s start
Imports:
import warnings
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from captum.attr import (
FeatureAblation,
LayerIntegratedGradients,
LLMAttribution,
LLMGradientAttribution,
TextTokenInput,
)
warnings.filterwarnings("ignore", ".*past_key_values.*")
warnings.filterwarnings("ignore", ".*Skipping this token.*")
Loading the model
def load_model(model_name, bnb_config):
n_gpus = torch.cuda.device_count()
max_memory = "9000MB"
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto",
max_memory = {i: max_memory for i in range(n_gpus)},
)
tokenizer = AutoTokenizer.from_pretrained(model_name, token=True)
tokenizer.pad_token = tokenizer.eos_token
return model, tokenizer
def create_bnb_config():
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
# bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
return bnb_config
model_name = "Qwen/Qwen2.5-1.5B-Instruct"
bnb_config = create_bnb_config()
model, tokenizer = load_model(model_name, bnb_config)
The GPU I had access to could only handle small 1.5b model, but Qwen2.5-1.5B-Instruct will be enough
Setting up the input and generating the response
eval_prompt = "Michael works as a software engineer in Austin, Texas. In his free time, he enjoys"
model_input = tokenizer(eval_prompt, return_tensors="pt").to("cuda")
model.eval()
with torch.no_grad():
output_ids = model.generate(model_input["input_ids"], max_new_tokens=15)[0]
response = tokenizer.decode(output_ids, skip_special_tokens=True)
print(response)
Here we setup the gradients and attribution for LLMs
lig = LayerIntegratedGradients(model, model.model.embed_tokens)
llm_attr = LLMGradientAttribution(lig, tokenizer)
Let’s run it
# Skip BOS token
skip_tokens = [1]
inp = TextTokenInput(
eval_prompt,
tokenizer,
skip_tokens=skip_tokens,
)
target = "painting, traveling to different countries, and volunteering at community events."
attr_res = llm_attr.attribute(inp, target=target, skip_tokens=skip_tokens)
lig = LayerIntegratedGradients(model, model.model.embed_tokens)
llm_attr = LLMGradientAttribution(lig, tokenizer)
inp = TextTokenInput(
eval_prompt,
tokenizer,
skip_tokens=skip_tokens,
)
attr_res = llm_attr.attribute(inp, target=target, skip_tokens=skip_tokens)
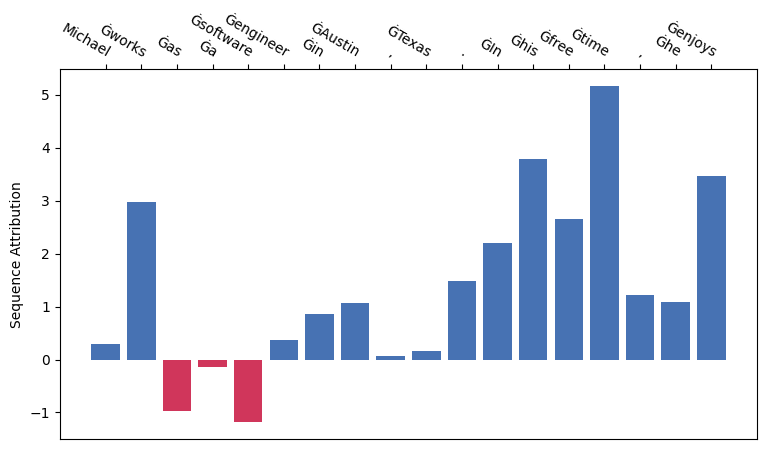
attr_res.plot_seq_attr(show=True)
Attribution table
attr_res.plot_token_attr(show=True)